Streaming data from FPGA: Using on-chip block RAM as buffer.
Introduction
This post continues the series of posts describing experiments with using an FPGA as a high-speed (millions of samples per second) data capturing device. It continues from my previous post, where we defined the exchange protocol and measured timing. As I concluded in that post, we need to have a buffer on the capturing device side, which can hold the samples if the computer temporarily stops polling the data due to handling OS interrupts.
Conveniently, FPGAs typically have RAM on the chip, which can be used for building such a buffer, and we will explore how to use it in this post. We will create a simple data generator that will simulate the data and write it into the buffer, and then read the data from the buffer and transfer it to the parallel bus.
This test program partially implements my project of building a microphone array with multiple INMP441 microphones connected to the FPGA, which I will briefly describe in the next section.
High level design overview
Here is the diagram of the digital device I am having in mind
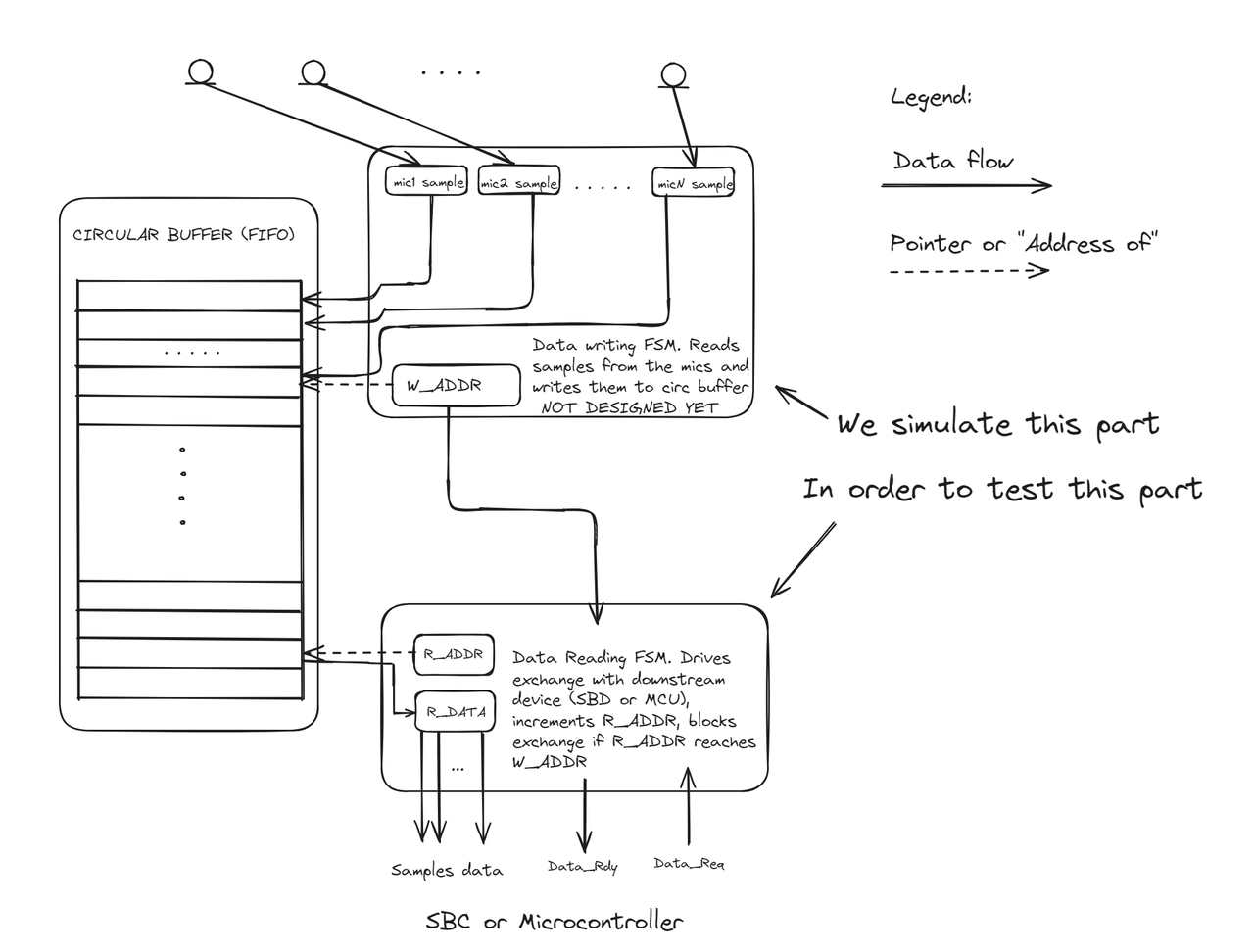
According to our estimation, we need a buffer of size > 260 samples. We will implement a 512-sample buffer, which will have extra space to cover cases when two interrupts come almost simultaneously.
The iCE40HX1K chip has 16 blocks of RAM, each with 4096 bits (512 bytes). Each block can be configured for storing 256 x 16-bit, 512 x 8-bit bytes, 1024 x 4-bit, or 2048 x 2-bit memory cells. Since I am aiming to capture 24-bit samples from multiple INMP441 microphones, my samples are 24-bit wide. To utilize the memory efficiently, I decided to use 3 blocks configured as 512x8: the 1st block will keep bits 0-7, the 2nd block will keep bits 8-15, and the 3rd block will keep bits 16-23.
We will design the multiple I2S capturing part in the next posts. Today, we will replace it with simulated data, which will be written into the circular buffer, and focus on data reading and transferring to the parallel bus.
The exchange protocol is the same as in the time measurement setup described in the previous post: the "device" (FPGA) waits for the rising edge of the "Data Req" (data request) line and sets its 21-bit data output, but this time it reads it from the memory instead of using a timer value. Then the "device" sets the "Data Rdy" (data ready) line to HIGH. The polling program detects the change in the "Data Rdy" line, reads and records the 21-bit data value from the parallel bus, and then sets "Data Req" to low on the SBC. This signals to the device that the SBC has successfully read the data, prompting it to set "Data Rdy" to low. The polling program detects the falling edge of the "Data Rdy" line and proceeds to the next cycle iteration.
Previously, we used the timer value as the data. It is pretty much the same in this design, but the timer value is written to the FIFO buffer, and the reading part of the system gets it from the reading side of the FIFO and sends it to the parallel bus.
The timer is now 8-bit wide. We repeat it 3 times to get a 24-bit value, so the data should be the least significant 21 bytes of the 24-bit value {Timer[7:0], Timer[7:0], Timer[7:0]}. As a quick reminder, we are using a 21-bit data value because we ran out of pins on the iCEstick board.
Verilog implementation
I think there are modules similar to PLL (see the previous post) which can be used for defining the RAM block in Verilog. The Memory Usage Guide for iCE40 Devices mentions the SB_RAM512x8, SB_RAM1024x4 modules, but I think they are Lattice/iCE40-specific and I am not sure how to use them with apio.
There is also another, more portable way to infer RAM blocks in Verilog, which is supported by most of the FPGA synthesis tools. We will follow this way in our design. The following code snippet shows how to define a 512x8 memory block in Verilog which can be inferred as a Block RAM by the synthesis tool.
module ram512x8 ( input [8:0] RADDR, input RCLK, input RE, output reg [7:0] RDATA, input [7:0] WDATA, input [8:0] WADDR, input WCLK, input WE ); reg [7:0] memory [0:511]; integer i; initial begin for(i = 0; i < 512; i++)// start with blank memory with 0 instead of x so that we can infer Yosys for BRAM. memory[i] <= 8'd0; end always @(posedge RCLK) begin if (RE) begin RDATA <= memory[RADDR]; end end always @(posedge WCLK) begin if (WE) begin memory[WADDR] <= WDATA; end end endmodule
When the synthesis tool sees an array of registers with a specific read and write access pattern, which matches the RAM block (like one above), it will infer the RAM block instead of using the LUTs.
Here is how we define the buffer in our top-level module:
//Define memory access signals wire [8:0] r_addr; wire r_en; wire [23:0] memory_read_value; reg [8:0] w_addr; reg [7:0] w_data; reg w_en; //We will use 3 blocks of 512x8 RAM to store 24-bit samples //Each the blocks share read address (r_addr), write address (w_addr), //write enable (w_en) and read enable (r_en) signals. We write the same //value to all 3 blocks, (since it is simulated data), and read the data into //different bits of the memory_read_value signal. ram512x8 ram512X8_inst_0 ( .RDATA(memory_read_value[7:0]), .RADDR(r_addr), .RCLK(ref_clk), .RE(r_en), .WADDR(w_addr), .WCLK(ref_clk), .WDATA(w_data), .WE(w_en) ); ram512x8 ram512X8_inst_1 ( .RDATA(memory_read_value[15:8]), .RADDR(r_addr), .RCLK(ref_clk), .RE(r_en), .WADDR(w_addr), .WCLK(ref_clk), .WDATA(w_data), .WE(w_en) ); ram512x8 ram512X8_inst_2 ( .RDATA(memory_read_value[23:16]), .RADDR(r_addr), .RCLK(ref_clk), .RE(r_en), .WADDR(w_addr), .WCLK(ref_clk), .WDATA(w_data), .WE(w_en) );
The simulation part is pretty simple, we generate the data and write it into each buffer:
reg [4:0] counter; //Controls stage of writing data into the buffer reg [7:0] counter2; //Counter representing the simulated data always @(posedge ref_clk) begin if (rst) begin w_addr <= 9'b0; counter <= 0; counter2 <= 0; w_en <= 0; end else begin if (counter == 3) begin counter <= 0; w_data <= ~counter2; end else if (counter == 4) begin w_en <= 1; end else if (counter == 5) begin w_en <= 0; end else if (counter == 6) begin counter2 <= counter2 + 1; w_addr <= w_addr + 1; end counter <= counter + 1; end end
The average reading speed should be faster then writing speed. If the reader is interrupted for a brief period of time, the data will be buffered in the RAM. When the reader returns to polling the data, it will catch up with the writer. If the reader reaches the writer address, it will stop reading the data until the new data arrives.
I implemented the reader in a separate model since want to reuse it in different designs. Here is the verilog code for the reading part:
module parallel_exchange_fsm ( input rst, //Reset input clk, //12 MHz iCEstick clock input [8:0] w_addr, //Current writing position so we know how much data is available //Interraction with memory output reg [8:0] r_addr, //Reading address in buffer output reg r_en, //Read enable input [23:0] memory_read_value, // //Interraction with downstream device input data_req, //Data request signal output reg [23:0] data_out, //Output data output reg data_ready //Data ready signal ); //Data request synchronization flip-flops reg data_req_1; reg data_req_2; localparam WAITING_DATA_REQ_HIGH = 2'b00; localparam WAITING_DATA_AWAIL = 2'b01; localparam READING_BUFFER = 2'b10; localparam WAITING_DATA_REQ_LOW = 2'b11; reg [1:0] paralled_data_io_state; //This FSM handles parallel data output always @ (posedge clk) begin if (rst == 1'b1) begin r_addr <= 9'b0; data_out <= 24'b0; data_ready <= 1'b0; data_req_1 <= 1'b0; data_req_2 <= 1'b0; paralled_data_io_state <= 2'b0; end else begin case (paralled_data_io_state) WAITING_DATA_REQ_HIGH: begin r_en <= 1'b1; //Just keep r_en high all the time for simplicity if (data_req_1 & ~data_req_2) begin paralled_data_io_state <= WAITING_DATA_AWAIL; end end WAITING_DATA_AWAIL: begin if (w_addr != r_addr) begin //Data available in the buffer paralled_data_io_state <= READING_BUFFER; end end READING_BUFFER: begin r_addr <= r_addr + 1; data_ready <= 1'b1; data_out <= memory_read_value; paralled_data_io_state <= WAITING_DATA_REQ_LOW; end WAITING_DATA_REQ_LOW: begin if (~data_req_1) begin paralled_data_io_state <= WAITING_DATA_REQ_HIGH; data_ready <= 1'b0; end end endcase data_req_1 <= data_req; data_req_2 <= data_req_1; end end endmodule
Note that if there is no data in the buffer, r_addr == w_addr, the reader will stick in the WAITING_DATA_AWAIL state until the new data arrives.
This is how we use it in the top-level module:
parallel_exchange_fsm parallel_exchange_fsm_inst ( .rst(rst), //Reset .clk(ref_clk), //12 MHz iCEstick clock .w_addr, //Current writing position so we know how much data is available //Interaction with memory .r_addr(r_addr), //Reading address in buffer .r_en(r_en), //Read enable .memory_read_value(memory_read_value), // //Interaction with downstream device .data_req(data_req), //Data request signal .data_out(data_out), //Output data .data_ready(data_rdy) //Data ready signal );
Tests and results
First of all we need to double check that the synthesis tool could infer the RAM blocks. We can do this by looking at the synthesis report generated by apio build command in "verbose" mode.
apio build --verbose ....Skipping some (a lot of) output... Info: Device utilisation: Info: ICESTORM_LC: 100/ 1280 7% Info: ICESTORM_RAM: 3/ 16 18% Info: SB_IO: 28/ 112 25% Info: SB_GB: 4/ 8 50% Info: ICESTORM_PLL: 0/ 1 0% Info: SB_WARMBOOT: 0/ 1 0%
Look for the "ICESTORM_RAM" line. We consumed 3 RAM blocks as expected, so the synthesis tool inferred the RAM blocks correctly.
The C part is almost the same as in the previous article, the only difference is that we read few hundres/few thousands of samples from the device and print the data instead of storing it in the binary file:
int main(int argc, char *argv[]) { //Reading 500Mb of data from the GPIO const unsigned samples_count = 2500; uint32_t *buffer = (uint32_t*) malloc(samples_count * sizeof(uint32_t)); poll_data_from_gpio(buffer, samples_count); //Calculate the ticks difference between each sample in place for (int i = 0; i < samples_count - 1; ++i) { char *ptr = (char*)(buffer + i); printf("%02X %02X %02X\n", (int)(*ptr), (int)(*(ptr + 1)), (int)((*(ptr + 2)) & 0x1F) ); } return 0; }
Compile and test the code:
>gcci -o3 test -o test test.c >sudo ./test Done !!! FF FF 1F FE FE 1E FD FD 1D FC FC 1C FB FB 1B FA FA 1A F9 F9 19 F8 F8 18 F7 F7 17 F6 F6 16 F5 F5 15 F4 F4 14 F3 F3 13 F2 F2 12 F1 F1 11 F0 F0 10 EF EF 0F EE EE 0E ED ED 0D EC EC 0C EB EB 0B EA EA 0A E9 E9 09
The data is read correctly, hooray!
Conclusion
We learned how to use RAM in iCE40 FPGA and implemented FIFO buffer. In the next article, we will learn how to read the data from multiple I2S microphones and push it into the FIFO buffer. Stay tuned!
References
The source code for this article is available at Github
Comments